Introduction
As a way to continue learning AWS and in preparation for future certifications I want to do some experiments on AWS. Each experiment will be easily replicable and will allow you to test it.
This first experiment is foundational and is focused on finding a fast way to create a controlled number files of known (small) size.
Conclusion if you don’t want to read it all:
Create a big file with dd and then spliting it is by far more efficient than using dd in a for-loop for files under 100k.
For example to create 128 files of 10k use the following commands
dd if=/dev/urandom of=random.img count=128 bs=10k
split -n 128 random.img
rm random.img
Conditions
- Use of AWS
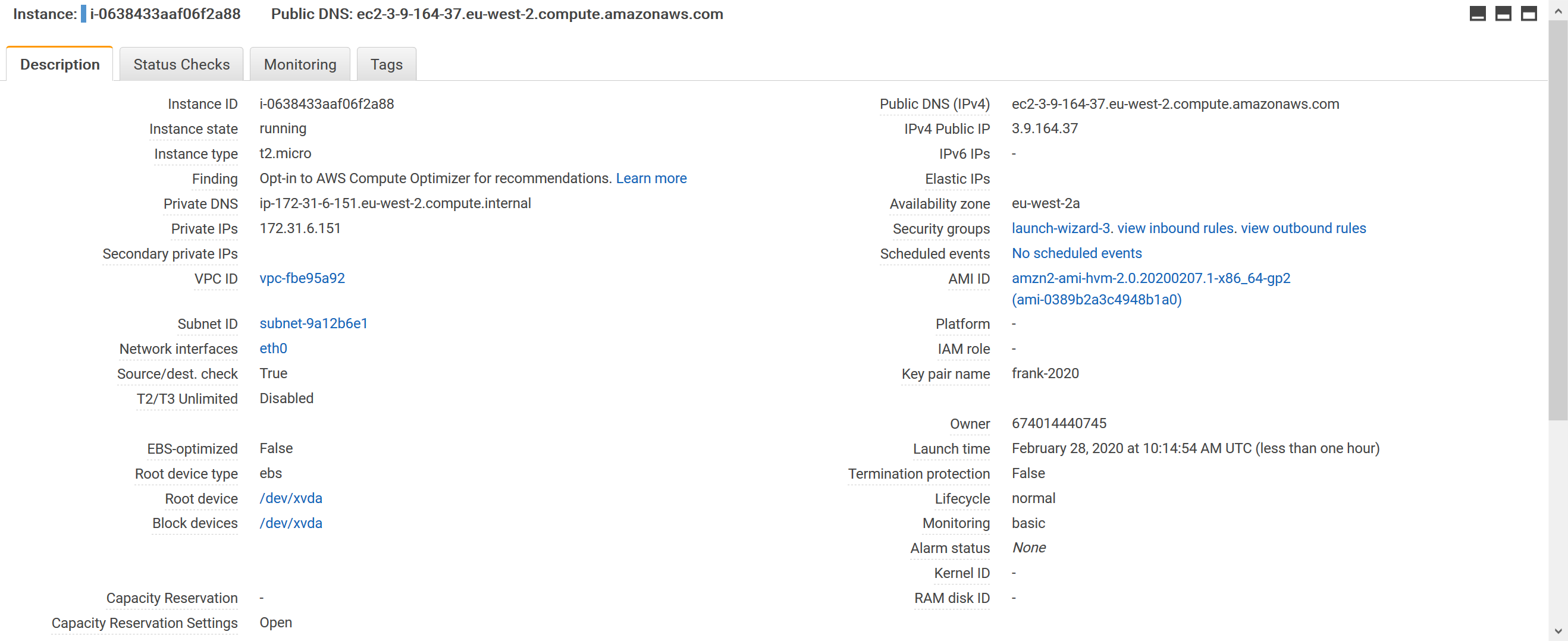
- t2.micro with 8 GB gp2 disk all default
- AMI amzn2-ami-hvm-2.0.20200207.1-x86_64-gp2 (ami-0389b2a3c4948b1a0)
- Linux ip-172-31-6-151.eu-west-2.compute.internal 4.14.165-131.185.amzn2.x86_64 #1 SMP Wed Jan 15 14:19:56 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
POMO
Purpose:
Being able to generate in a speedy manner many files with random content
Objective
Find a good way to generate lots of small files for future tests between running multiple times dd versus one dd and one split
method
Testing 2 approaches
- 1.1 - using a for-loop with dd
- 1.2 - using a single dd to generate a big file and the use split to create many small files
Outcome
A script using the winning method.
Assumptions:
- use of dd from urandom to avoid a simple syscall to reserve space on disk
- use of sync after each experiment to make sure data is on disk (and not on cache)
- use of time (the shell command) to get the measuring data
- the difference of time between run time and user+sys is time used to write on disk and due to disk speed and filesystem config
Possible other experiments
- test with bigger files
- test with more files
- on different disks speed
- on different disks size
- on different technology disks (EFS)
- on different instances
- changing kernel for disk cache values
- changing the filesystem parameters
- changing the filesystem
Experimental Script
This bash script is simple and tests both mutiple dd in a for-loop and single dd + split
#!/bin/bash
EXP1NAME=exp1-many-files
[ -z "$2" -o -z "$1" ] && echo "FAILURE need 2 parameters: param1 is size of each file (e.g. 10k), param2 is number of final files" && exit
EXP1SIZE=$1
EXP1COUNT=$2
echo "parameters are all good"
echo "EXP1SIZE = $EXP1SIZE"
echo "EXP1COUNT = $EXP1COUNT"
# back to home dir
cd $HOME
rm -rf ${EXP1NAME}.1 2> /dev/null
mkdir ${EXP1NAME}.1
rm -rf ${EXP1NAME}.2 2> /dev/null
mkdir ${EXP1NAME}.2
echo '*************** START OF EXPERIMENT 1.1 ***************'
date
# experiment 1.1 using dd to generate many small file with a for bash loop
cd $HOME
cd ${EXP1NAME}.1
time for ((i=1; i<=$EXP1COUNT; i++)); do dd if=/dev/urandom of=random-${i}.img count=1 bs=${EXP1SIZE} >/dev/null 2>&1; done
echo "sync"
time sync
date
echo 'END OF EXPERIMENT 1.1'
echo
echo
echo '*************** START OF EXPERIMENT 1.2 ***************'
date
# experiment 1.2 using dd to generate 1 big file then split to split
#we use random data to make sure data is written.
cd $HOME
cd ${EXP1NAME}.2
echo "Generating one file by adding ${EXP1COUNT} blocks of ${EXP1SIZE} with random content from /dev/urandom"
time dd if=/dev/urandom of=random.img count=${EXP1COUNT} bs=${EXP1SIZE} > /dev/null 2>&1
sync
echo "splitting the file into ${EXP1COUNT} pieces"
time split -n ${EXP1COUNT} random.img
echo "sync"
time sync
date
echo 'END OF EXPERIMENT 1.2'
RUNS
experiments
- create 10 files of 10k - testing that is all works
- create 10,000 files of 10k bs=10k - baseline
- create 100,000 files of 1k bs=1k - disk should be faster to write?
- create 1000 files of 100k bs=100k less files more size. FS will play a bigger role
bash commands for the runs
- ./exp1-many-files.sh 10k 10
- ./exp1-many-files.sh 10k 10000
- ./exp1-many-files.sh 1k 100000
- ./exp1-many-files.sh 100k 1000
execution and raw results
RUN1
[ec2-user@ip-172-31-6-151 ~]$ ./exp1-many-files.sh 10k 10
parameters are all good
EXP1SIZE = 10k
EXP1COUNT = 10
*************** START OF EXPERIMENT 1.1 ***************
Fri Feb 28 11:31:27 UTC 2020
real 0m0.009s
user 0m0.007s
sys 0m0.001s
sync
real 0m0.011s
user 0m0.000s
sys 0m0.000s
Fri Feb 28 11:31:27 UTC 2020
END OF EXPERIMENT 1.1
*************** START OF EXPERIMENT 1.2 ***************
Fri Feb 28 11:31:27 UTC 2020
Generating one file by adding 10 blocks of 10k with random content from /dev/urandom
real 0m0.001s
user 0m0.001s
sys 0m0.000s
splitting the file into 10 pieces
real 0m0.001s
user 0m0.001s
sys 0m0.000s
sync
real 0m0.003s
user 0m0.001s
sys 0m0.000s
Fri Feb 28 11:31:27 UTC 2020
END OF EXPERIMENT 1.2
RUN2
[ec2-user@ip-172-31-6-151 ~]$ ./exp1-many-files.sh 10k 10000
parameters are all good
EXP1SIZE = 10k
EXP1COUNT = 10000
*************** START OF EXPERIMENT 1.1 ***************
Fri Feb 28 11:32:15 UTC 2020
real 0m8.202s
user 0m6.547s
sys 0m1.504s
sync
real 0m0.138s
user 0m0.001s
sys 0m0.000s
Fri Feb 28 11:32:23 UTC 2020
END OF EXPERIMENT 1.1
*************** START OF EXPERIMENT 1.2 ***************
Fri Feb 28 11:32:23 UTC 2020
Generating one file by adding 10000 blocks of 10k with random content from /dev/urandom
real 0m0.565s
user 0m0.000s
sys 0m0.560s
splitting the file into 10000 pieces
real 0m0.336s
user 0m0.024s
sys 0m0.276s
sync
real 0m1.782s
user 0m0.003s
sys 0m0.000s
Fri Feb 28 11:32:27 UTC 2020
END OF EXPERIMENT 1.2
RUN 3
[ec2-user@ip-172-31-6-151 ~]$ ./exp1-many-files.sh 1k 100000
parameters are all good
EXP1SIZE = 1k
EXP1COUNT = 100000
*************** START OF EXPERIMENT 1.1 ***************
Fri Feb 28 11:32:53 UTC 2020
real 1m18.358s
user 1m2.505s
sys 0m13.952s
sync
real 0m0.088s
user 0m0.001s
sys 0m0.000s
Fri Feb 28 11:34:11 UTC 2020
END OF EXPERIMENT 1.1
*************** START OF EXPERIMENT 1.2 ***************
Fri Feb 28 11:34:11 UTC 2020
Generating one file by adding 100000 blocks of 1k with random content from /dev/urandom
real 0m0.776s
user 0m0.076s
sys 0m0.670s
splitting the file into 100000 pieces
real 0m8.028s
user 0m0.232s
sys 0m3.323s
sync
real 0m0.940s
user 0m0.003s
sys 0m0.000s
Fri Feb 28 11:34:22 UTC 2020
END OF EXPERIMENT 1.2
RUN 4
[ec2-user@ip-172-31-6-151 ~]$ ./exp1-many-files.sh 100k 1000
parameters are all good
EXP1SIZE = 100k
EXP1COUNT = 1000
*************** START OF EXPERIMENT 1.1 ***************
Fri Feb 28 11:35:13 UTC 2020
real 0m1.342s
user 0m0.948s
sys 0m0.362s
sync
real 0m0.170s
user 0m0.001s
sys 0m0.000s
Fri Feb 28 11:35:15 UTC 2020
END OF EXPERIMENT 1.1
*************** START OF EXPERIMENT 1.2 ***************
Fri Feb 28 11:35:15 UTC 2020
Generating one file by adding 1000 blocks of 100k with random content from /dev/urandom
real 0m0.555s
user 0m0.004s
sys 0m0.546s
splitting the file into 1000 pieces
real 0m0.084s
user 0m0.004s
sys 0m0.076s
sync
real 0m1.520s
user 0m0.002s
sys 0m0.000s
Fri Feb 28 11:35:18 UTC 2020
END OF EXPERIMENT 1.2
in table form
| Runs | for-loop | dd + split |
|---|---|---|
| 1 | 0.02s | 0.005s |
| 2 | 8.34s | 2.683s |
| 3 | 78.446s | 9.744s |
| 4 | 1.512s | 2.159s |
Conclusion
For files of less than 100k it is much better to create a single big file and use split to split it. This is probably due to the amount of time a bash for-loop wastes on context switch in the kernel.